Spatiotemporal Sentiment Analysis of Instagram Posts in Helsinki
Organized for the third time at the University of Helsinki in May 2018, the Helsinki Digital Humanities Hackathon invited participants to take a swing at research problems from the humanities and social sciences using methods from computer science. The Hackathon concept is that small groups work together for a short, intense period of time to analyze data, set research questions and find solutions. This time there were five Hackathon groups, and participating students were free to choose the group they were most interested in.
My group Helsinki Geotagged Social Media was presented with a vast set of social media data about Helsinki, which has already been used by researchers in previous studies. The selection featured social media posts geotagged in Helsinki between 2014 and 2018: 1.3 million Instagram posts, 61,000 tweets and nearly 130,000 Flickr posts.
During the first three days of preparation, our team decided to work on the Instagram dataset, simply because it was the largest dataset we had and it was interesting. Also, we wanted to perform some sentiment analysis of all aspects of the Instagram post – captions, hashtags and emojis (and if time permits, the images as well), to see what areas of the Helsinki metropolitan region are the happiest. We even boldly presented our plan for the hackathon as “Happiness in social media” at the end of the preparation phase (first three days). Here is how our data looked if we simply plotted on a map without any processing:
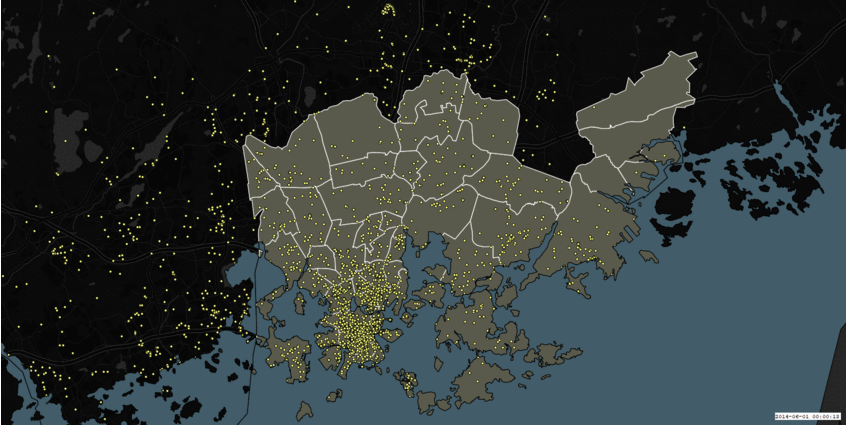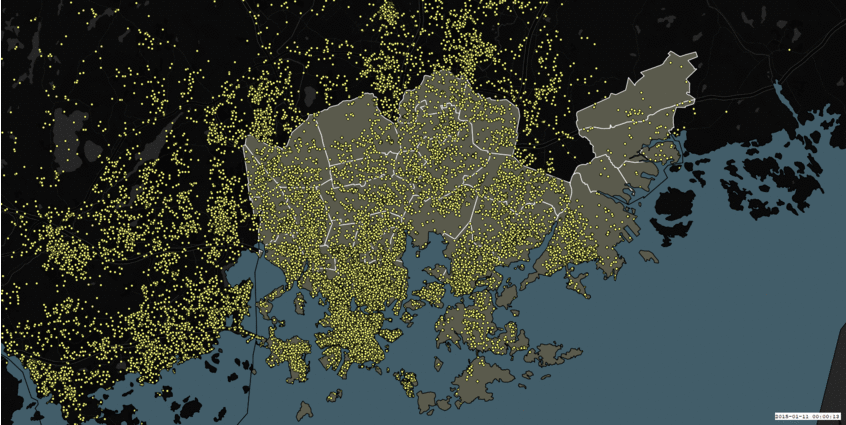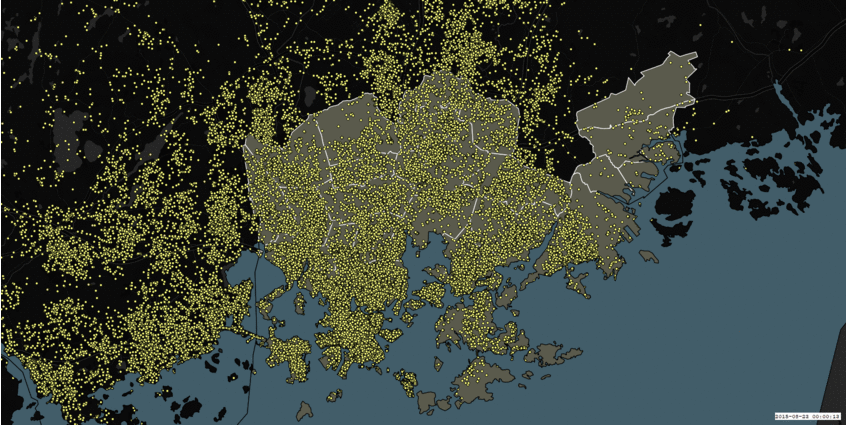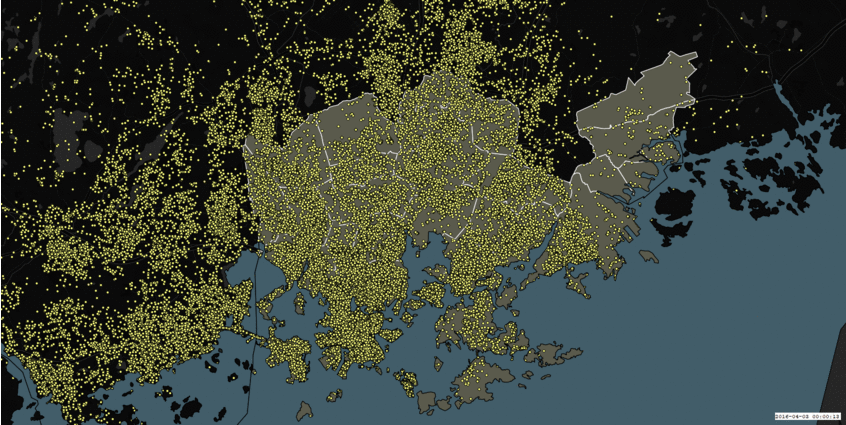
Figure 1: Instagram dataset on a map: Growth of Instagram posts over time
Over the next couple of days, we figured out that defining happiness and quantifying it over social media is not a low-hanging fruit. Especially because when there is the happiness bias, i.e. everyone pretends to be positive over social media as happy people, whatever results we can produce in one week would be misleading. Furthermore, sentiment analysis to computers is just positive (+ve), negative (-ve) or neutral (0), whereas in reality, the whole notion of human sentiments or emotions stretches over at least eight dimensions such as love, optimism, submission, awe, disapproval, remorse, contempt and aggressiveness. So eventually, we narrowed down from over-enthusiastic “happiness” to more realistic research questions on sentiments as following two explorations:
-
Spatial: How sentiment polarity is distributed in the neighbourhoods of Helsinki?
-
Temporal: What is the variation of sentiments over time?
While most of the other teams had clear objectives, ours was quite vague. However, the actual problem was to deal with the messy data that was inherently cluttered, multilingual and contained contents (text, emojis, hashtags) that could be completely random and not necessarily complement each other.
Since the core of our idea was to perform sentiment analysis, we used the following preprocessing strategies:
-
Remove all posts with no good text content by dropping posts with no text or containing just emojis and hashtags.
-
Restrict the posts that are only in English, because sentiment analysis for texts in languages other than English yields no good results at all.
-
Filter the posts that are in the Helsinki metropolitan region only. In other words, remove every post that was geotagged within Espoo or Vaanta region.
Now for the language detection, the available Python libraries were langdetect, langid, NLTK and fastText. We chose fastText, because it had pre-trained language identification models for 176 languages; it was fast and reliable. As the state-of-the-art library by Facebook Research, it was suitable for dealing with multilingual social media platforms like Instagram.
It is very common for people to use multiple languages while posting on social media. However, we wanted posts that are genuinely in English. So, using fastText we first tagged each post with a language to represent it as a language diversity treemap. We omitted all those posts that were tagged with multiple languages and retained the English posts which has a confidence score of more than 70%.
Then to restrict the posts within the Helsinki metropolitan region, we applied [custom neighbourhoods polygon map of Helsinki] and left all other points outside it. To divide Helsinki into discernible units, we could have also relied on Postcode division, Square grids or Land use division criteria.
At this point, we had reduced 1,316,705 Instagram posts from our initial dataset to 193,111 posts that are in English and within “Helsinki”.
SENTIMENT ANALYSIS
Now comes the heart of our idea – the sentiment analysis. I have previously done sentiment analysis of Tweets and it was not so difficult. Hence, I assumed that doing the same for Instagram would not be a big deal. Surprisingly, it was not the case!
Even though Twitter users use hashtags, they seem more disciplined than the users of Instagram. Instagram users tend to use hashtags as an integrated part of their sentences, however, many of them were random or associated with an event or global trend. Also, the overuse of Internet slang was an overkill for overanalysis. Nonetheless, we (thanks to Saara) created a manually annotated goal standard for the
polarity of sentiments for about 50 Instagram posts, and verified it against two sentiment analysis libraries.
Using Vader we performed sentiment analysis of the ‘text-only’ part of the caption that is without emojis and hashtags. This is actually where figured out that there is an excessive use of integrated hashtags in any given caption text. So, we then used Aylien API to analyze the whole caption as it is. We checked the results against our goal standard, and the comparison is shown in Figure 2.

Figure 2: Efficiency of sentiment analysis APIs (VADER vs Aylien) with manually annotated goal standard
RESULTS
As the last step, we used QGIS, a FOSS geographic information system (GIS) application, to put our results on a map. Here is the end product “Sentiments in Helsinki – Spatiotemporal Analysis of Instagram Posts”.
Figure 3 shows the number of people posting on Instagram from each sub-region of the Helsinki metropolitan area. Not so surprisingly, most posts are geotagged to the tourist part of Helsinki city centre (around Kamppi and Rautatieasema). This bias is also because Instagram picks locations coordinated from “Facebook’s tagged location” and not necessarily from the actual coordinates. Also, it is usual for people to tag “Helsinki” for anything that is happening around them.

Figure 3: Percentile density of Instagram posts per sub-region of Helsinki metropolitan area
Now, we wanted to see how user activities vary across different seasons. As shown in Figure 4, to our surprise user activity peaks during winter and goes down in summer. Initially, we had assumed that people post more during sunny seasons and they hibernate during cold seasons.

Figure 4: Instagram user activities in different seasons
To aid this result, we did a temporal analysis of sentiment polarity (Figure 5). It is evident that the positive polarity is seen during holiday season (Christmas and new year) as well as when the cold season begins i.e. the end of summer.

Figure 5: Temporal analysis of sentiment polarity
Last but not least, the dominant sentiments in the Helsinki region as per figure 6 show that the central touristic part of Helsinki, and some regions with parks. This is a noticeable positive-sentiment skew towards the centre is due to the location bias and tourist activities in that region.

Figure 6: Dominant sentiments in the Helsinki region
Instagram APIs didn’t allow us to crawl the images of the posts, nonetheless we manually checked all the images (posts) that were tagged with negative sentiments. It looks like below:

Figure 7: Posts tagged with negative sentiments
In the first picture, a person just gotten over a lonely time of their life and enjoying the beginning of their new phase of life with a special friend. While the photo and contextual meaning of the text were positive, due to negative words to describe the “lonely past”, this post had received a negative sentiment score. The second picture is of a person whose bike was punctured and the pic was taken while they were walking back home with a flat tyre. We didn’t notice anything positive about the post except that the person was happy to post it on Instagram. The third picture was of a happy hangover.
DELIVERABLES
Over the period of these 8 days of hackathon, we learned many new things, made good networking with peers from diverse fields of study, had enough free food/coffee/wine, etc. Besides that, we had: